Je wilt soms dat bepaalde pagina’s niet gevonden worden op internet. Dit kunnen test pagina’s zijn, advertentie pagina’s etc. Lees hier meer over: waarom zou je een pagina op no-index zetten.
Er zijn verschillende manieren om tegen een zoekmachine te zeggen: Hé, deze alstublieft niet indexeren. Ik wil niet dat deze pagina gevonden wordt in de zoekresultaten.
1 manier die hiervoor werd gebruikt was met de robots.txt. Niet doen!
Elke website heeft een robots.txt (nodig)
Het hebben van een (werkende) robots.txt is een must. Zoekmachines en andere bots gebruiken jouw robots.txt om aanwijzingen te ontvangen. Aanwijzingen in de zin van: hier mag je wel naartoe, hier mag je niet naar to
Daanaast kun je de robots.txt gebruiken om aan te geven waar je XML Sitemaps te vinden zijn. Je kunt eenvoudig een regeltje toevoegen die hen wijst naar de juiste URL van de sitemaps. In de meeste gevallen is dat jouwdomein.nl/sitemap.xml Maar dat even terzijde.
“Surfer SEO is 1 van de beste SEO tools die je niet mag missen.“
Met Surfer SEO scoor je hoger in Google, zonder backlinks!

Het missen van een robots.txt geeft je dus veel minder speelruimte en kan daarbij ook nog eens een negatieve invloed hebben op je website prestaties in de zoekmachines. Het verkeerd gebruiken van je robots.txt is misschien nog wel erger, omdat je dan wellicht de google bot of bing bot weigert toegang te verlenen tot je site, met alle gevolgen van dien.
In het kort:
Een robots.txt is eigenlijk een menukaart of plattegrond voor jouw website. Elke bezoeker (in het geval van robots) kan zien waar ze wel of niet naartoe mogen gaan.
Waarom mag je dan een robots.txt niet gebruiken om een pagina op no-index te zetten?
In het kort gezegd heeft Google nooit deze manier van pagina’s op no-index zetten aangemoedigd of gedocumenteerd.
In juli 2019 hebben ze de beslissing genomen dat ze deze regels niet langer meer worden ondersteunen.
Wat Google zegt: https://webmasters.googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html
While open-sourcing our parser library, we analyzed the usage of robots.txt rules. In particular, we focused on rules unsupported by the internet draft, such as crawl-delay, nofollow, and noindex. Since these rules were never documented by Google, naturally, their usage in relation to Googlebot is very low. Digging further, we saw their usage was contradicted by other rules in all but 0.001% of all robots.txt files on the internet. These mistakes hurt websites’ presence in Google’s search results in ways we don’t think webmasters intended.
Het is daarom niet verstandig om je robots.txt te gebruiken om bepaalde pagina’s niet meer te laten indexeren.
Daarbij is het volgende belangrijk om te weten:
Een noindex-instructie is alleen effectief als de pagina niet wordt geblokkeerd door een robots.txt-bestand! Als de pagina wordt geblokkeerd door een robots.txt-bestand, ziet de crawler of bot de noindex-instructie niet. De pagina kan dan nog steeds worden weergegeven in zoekresultaten, bijvoorbeeld als andere pagina’s een link naar deze pagina bevatten! Onthoud dit dus goed.
Wat moet je doen als je dit toch via je robots.txt hebt gedaan?
Allereerst moet je alle pagina’s die je uit wilt sluiten op een andere manier op no-index zetten.
Wanneer je de website met WordPress hebt gebouwd kun je de pagina’s 1 voor 1 uit de index laten halen, zoals in deze afbeelding:
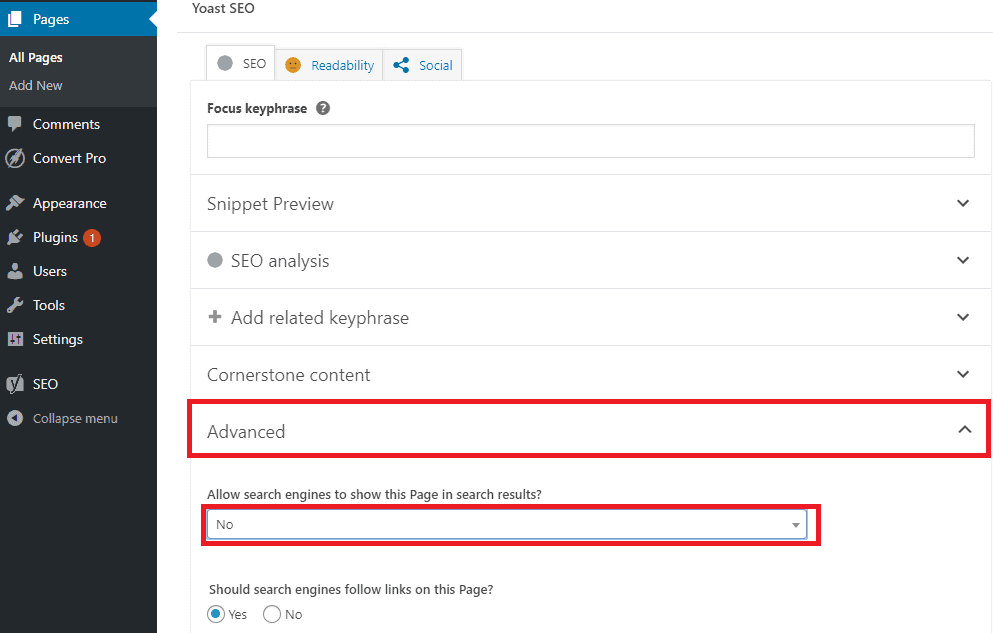
In principe zet hij dan een robots meta-tag in de (html) broncode van de pagina, waardoor de zoekmachine weet dat deze niet meer geïndexeerd moet worden. Dit zul je zelf niet zien, maar werkt wel makkelijk.
TIP:
Zet bijvoorbeeld al de URL’s van de pagina’s die je op no-index hebt gezet op 1 pagina, en laat vervolgens de zoekmachines deze ene pagina crawlen. Zie afbeelding. Dan zal de crawler alle URL’s in 1 keer zien en crawlen. Dit gaat sneller dan alle URL’s 1 voor 1 in Google Search Console te laten crawlen.
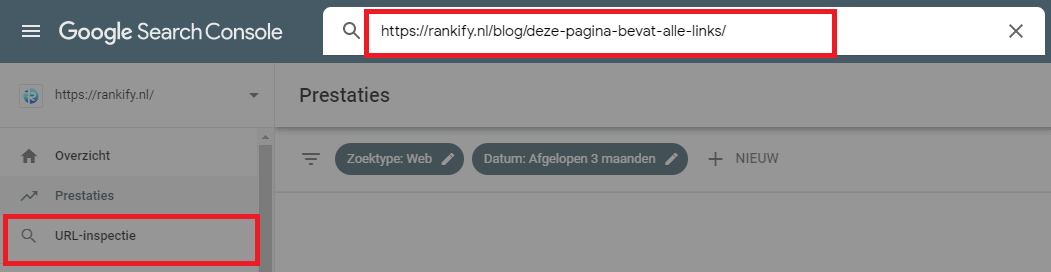
Nadat je de pagina’s op no-index hebt gezet moet je wachten tot Google en Bing de pagina’s hebben bezocht en de no-index tag hebben gezien.
Helaas zullen de pagina’s nog niet direct uit de index verdwijnen.
Google heeft geen optie om alle pagina’s in 1 keer te laten verdwijnen uit de zoekresultaten, maar je kunt ze wel 1 voor 1 laten verdwijnen, per direct. Lees daarvoor ons blog: Webpagina verwijderen uit Google
Er zijn nog meer manieren om een pagina op no-index te zetten, die hier niet worden besproken, zoals via het .htaccess bestand, via Tag Manager, aparte plugins, scripts etc.
Hulp nodig bij het optimaliseren van jouw website?
Laat hieronder je gegevens achter en wij helpen je verder.
Veelgestelde vragen:
In het kort: Waarom geen pagina’s op noindex zetten in je robots.txt ?
Google negeert de instructies in de Robots.txt die verwijzen naar noindex van bepaalde pagina’s. Het heeft dus geen zin. Je moet de noindex echt op pagina niveau instellen.
Wat is een robots.txt ?
Een robots.txt is eigenlijk een menukaart of plattegrond voor jouw website. Elke bezoeker (en in dit geval bots) kan zien waar ze wel en niet naartoe mag gaan.
Waar moet je dan de noindex instellen?
Je doet dit op pagina niveau. Dus op elke pagina apart moet in de header worden aangegeven dat de pagina niet geïndexeerd moet worden.

